AI SOFTWARE
The Platform for GenAI Solutions
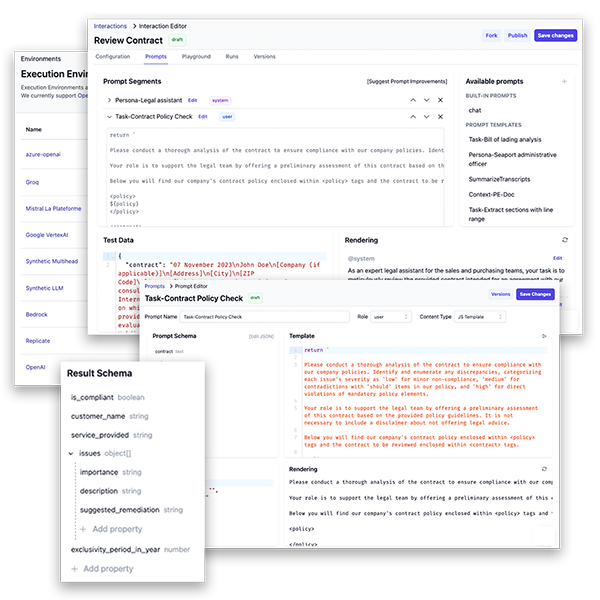
With Vertesia's Large Language Model (LLM) software platform, enterprise teams design, test, deploy, and operate LLM-powered tasks that automate and augment their business processes and applications with security, governance, and orchestration to drive efficiency, improve performance, and lower costs.













Load Balancing
Distributed tasks on models, based on weights
Shadowing
Execute in shadow of main model for evaluation
Multi-Head
Several LLMs execute the task, an evaluator selects the best one to be served, label all
Self-Training
Automatically fine-tune less performing models with the results selected by LLM or human feedback
Self-Improvement
Iterate on Self-Training to have the model converge and specialize on the task







